
1、科学将成为人工智能的主战场,创新源于底层突破并与实际需求相结合
如今,人工智能在中国的发展如火如荼,各类应用如自动驾驶、机器人、计算机视觉、自然语音处理、人脸识别等层出不穷。鄂维南院士指出,这些固然是人工智能非常好的应用领域和场景,但更应认识到,科学将成为人工智能的主战场,而新一代人工智能的基础其本质问题就是数学的问题。
鄂维南院士总结了数学史上的三大里程碑。第一个时代是牛顿时代,牛顿的工作明确无误地奠定了数学成为自然科学的语言的地位。第二个时代是冯诺伊曼时代,让我们认识到科学计算是通往应用的主要桥梁。第三个时代是当今时代,作为人工智能和科学研究新范式的基础,数学走到了科学和技术创新的最前沿。
在其中,机器学习将成为推动应用数学的主动力。通过机器学习和传统应用数学的方法的结合,可以解决很多实际问题,包括指纹、图像、自然语言等等。鄂院士以与学生邰骋、汤林鹏联合创办的墨奇科技为例,指出墨奇科技从基本原理出发,探索非结构化数据库的突破性的创新,结合应用场景之一生物特征识别认证,从算法到软件到平台实现,再到产品落地,解决了身份认证的现实挑战。
以指纹识别来说,从技术架构上,只有深度学习是不够的。这是因为,深度学习有很大的局限性,如易受噪声干扰,具有内蕴的不稳定性,可解释性差,精度有瓶颈,需要大量标注数据等。
鄂院士指出,墨奇的技术架构从最原始的基本原理出发,也就是图像的编码、最有效的几何表示、索引、搜索算法和相应的系统等等,兼容深度学习,并达到了前所未有的速度和精度,比如在10亿指纹库达到秒级的搜索,而且精度非常高,正确答案排名前三率高达 99.99 %。除了精准可靠,生物识别还要保护隐私,包括结合疫情现实需求,墨奇构建了非接触的指纹采集认证系统。
鄂院士指出,在做科研的过程中会做一些模型和算法,而在这个基础上,甚至可以做一些产品,要做到这件事情,就必须要重视在落地方面各种功能的需求和市场的需求,这方面的思维对做应用数学的人来说也是不可或缺的。
2、生物识别的基本原理:为什么 1:N 识别难度远大于 1:1 验证?
邰骋在演讲中进一步阐释了保护隐私的生物识别。随着包括人脸识别在内的生物识别被广泛应用,隐私泄露问题逐渐引起人们的广泛关注。邰骋介绍了生物识别技术的原理,以及如何构造保护隐私的生物识别技术,让生物特征变得像密码一样可以修改,实现生物特征领域的公钥签名机制。

在日常生活中,身份认证的场景随处可见,比如门禁、考勤打卡、交易支付、交通出行等。邰骋介绍,通常身份认定的方式基本上是三类:一是基于你知道的信息,例如密码和口令;二是基于你拥有的东西,比如说U盾、身份证等;三是基于你的生物特征,包括指纹、人脸、虹膜、掌经脉、声纹、步态、足迹等身份特征。
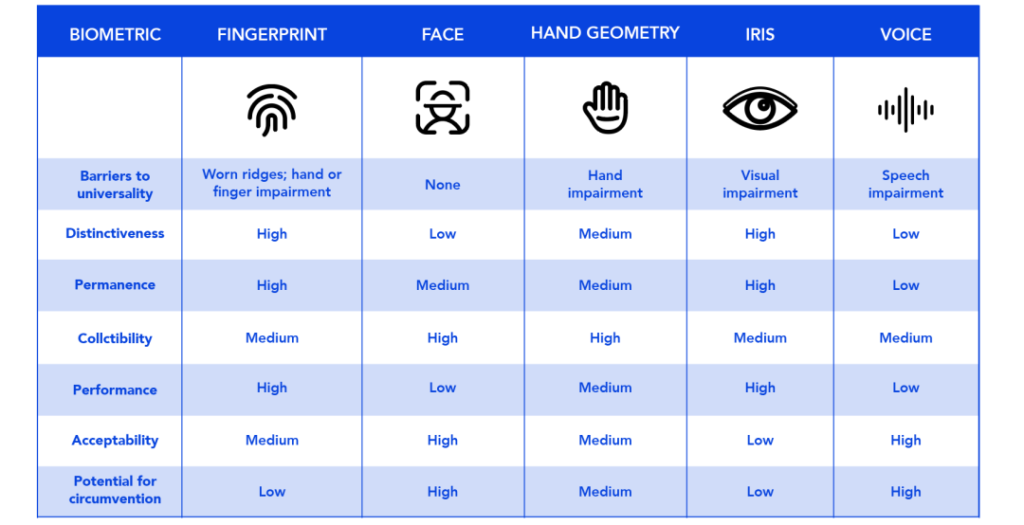
生物特征比对方式,一般来说有两种。一种是验证,也称之为 1:1 的比对。二是识别,也称之为 1:N 的比对:
- 验证,是看这个人是不是他所宣称的人,例如手机解锁、去机场做身份证和人脸的核验等,都是属于 1:1 的验证问题,这相对比较容易。
- 识别,是 1:N 的问题,要回答的是这个人是谁。他可能没有证件,或者你不相信他是他宣称的人,只根据生物特征来进行识别身份。在身份核验或者黑名单查询等,这类应用就是一个 1:N 识别的问题,而且随着库容增大,会变得更加困难。

生物识别系统是用相似度来进行比对的,也就是衡量输入的相似程度来取一个阈值,如果说相似度高于这个阈值就接受,如低于这个阈值就不通过。如果说把相似度分数画下来,一个真的比对分数是比较高的,通常会在偏右的一方。如果说是错误比对,分数会比较低,在左边一方。但是他们可能有重叠。因为有重叠,所以系统会犯两种错误:
- 错比(false match/false accept):把不同的人当成同一个人。
- 漏比(false nonmatch/false reject):把同一个人当成不同的人。
1:N 的问题会比 1:1 的问题要困难很多。对于上面两类错误,我们可以用下面这个公式估算 1:N 的系统和 1:1 的系统的错误率。

下标N是指有 N 个人的 1:1 的识别,可以看到两类系统漏比率基本相当,而错比率 1:N 系统近似于是 1:1 系统的N倍。比如说 1 亿人的库的比对,和 1 万人的库的比对,可以说难度完全不同,几乎不是同一个问题。

针对这一点,在实际的应用中,参数选取是不同的。比如说有一些对安全性要求比较高的应用,主要关心的不要放坏人进来,所以对错比的控制要求非常高,但是漏了一点不要紧。而在刑侦应用当中,因为需要给定的现场指纹,要给定一些候选人的列表,同时因为有指纹专家人工核验,错一点不要紧,反而不希望漏过坏人,所以漏比是比较重要的。大部分的应用是在两者之间的,具体是什么样的参数,在实际应用当中是根据具体应用情况来确定的。
3、从技术角度看,如何设计保护隐私的生物识别系统?
生物识别的隐私泄露比账号密码泄露的严重得多,和密码不同,生物特征一旦泄露就永远泄露,所以对生物识别系统的安全的考量要比一般的账号密码要更高。
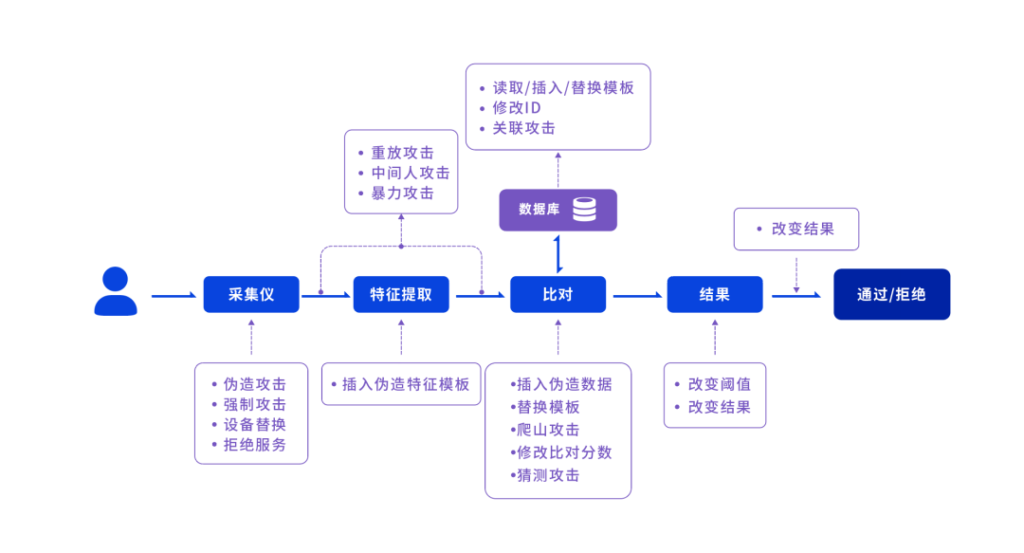
邰骋指出,一般来讲,无论是 1:1 系统还是 1:N 系统,都要通过一个基本的流程:采集、特征提取、比对、输出结果,给定是通过还是拒绝。而在这样系统中每一个环节,都有不同的攻击方式如下:
那么,设计保护隐私的生物识别系统要满足怎样的性质?邰骋表示,这一点业界有很多的讨论,并没有一个完整的共识,但是以下三点需要被满足:
- 第一,不可逆。用户的原始特征和采集到的模板,都被认为是用户的隐私信息,都应该被保护,而我们用来比对的是变换的特征,并存在数据库里。不可逆指的是,在给定比对特征的情况下,恢复原始的特征模板是非常困难的,最好是不能恢复的。
- 第二,可撤销。这一点可以参照密码的使用,比如说账号密码泄露后,我们是可以修改密码的。在生物特征当中,我们也希望可以做到这一点,一旦某一个模板泄露,我可以安全注销,然后签发一个新模板,这样就使得使用生物识别的方式和我们使用密码的方式一样可撤销。
- 第三,非关联性。我们希望用户有不同的生物识别应用,彼此之间并不关联,比如说有小区门禁的应用,支付的应用等等,并不交叉认证,这是非关联性的一个最基本的要求。
因此可以看到,保护隐私的生物识别是比较困难的问题,而现有系统很难达到。那我们通过什么途径去才能构造保护隐私的生物识别技术,才能达到上面的三个性质呢?
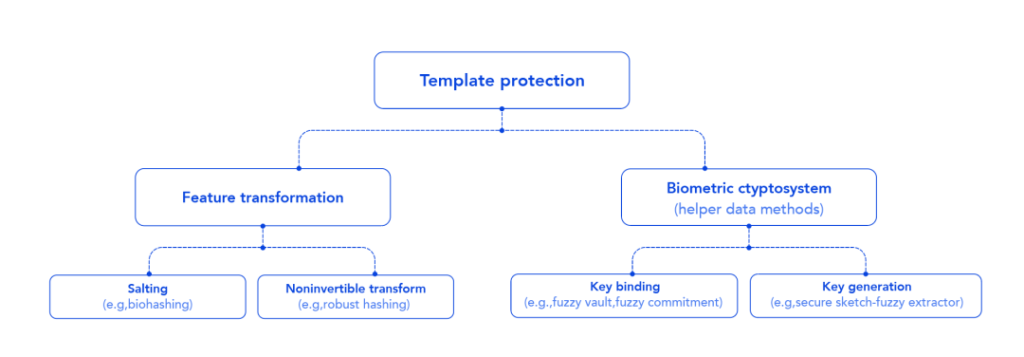
邰骋认为,核心的问题是对特征模板做保护。保护有两类,一类是通过对特征做某种变换,从而达到保护的目的;另一类是与密码系统相结合,可以构建一种生物密钥系统。构造保护隐私的生物识别技术还是一项在进行中的工作,目前有四个主要的方向:Salting,不可逆变换,Biometric Key,以及 Key-binding 生物密钥系统。

这四类实现方式在安全性来源、存储和比对精度的不同。
- 在安全性来源方面:第一种Salting的安全性来自于密钥是秘密的;第二种不可逆变换的安全性来自于函数的不可逆性;第三种生成密钥,它的安全性主要取决于多少信息被保留下来,放弃了多少信息;在第四种生物密钥中,则取决于辅助信息设计等。
- 从存储来看:在 Salting 的做法下,它是存了一个变换后的模板和一个 Key。在不可逆的变换下,它存储这个变换后的模板也存了一个 Key。在密钥生成模式下,没有存这个 Key,只存了变换的值。在生物密钥系统下,可以存一些辅助信息等等。后两种情况下,原始模板都没有被保存。
- 在比对精度方面:在 Salting 做法下,可以变换到跟原来模板同样的空间来做比对。在不可逆变换下,可能也是在原始变换空间内做比对。在密钥生成和密钥绑定的系统下,都可以使用纠错码来实现一定的纠错,然后再进行对比。
这四种方式都是业内正在探索的方向,特别是生物密钥系统和生物密钥绑定和生成这两种方法,有天生不用存密钥的优势,可以用来做一些真正保护隐私的识别。这是一个非常吸引人的领域,其中有很多问题都可以被转化为应用数学的问题,同时也是一个比较大的空白领域,有非常多激动人心的问题,需要业界共同努力进一步解决。
这也正是墨奇科技持续努力的领域,墨奇科技也将继续致力于为数十亿人提供保护隐私、安全可靠的下一代身份认证和识别服务,研发先进的人工智能技术来自动化地处理机器知识,最终增强人类处理信息的能力。