
在身份识别领域,特征的稳定性一直是影响认证精度的重要因素。为了支持特征提取的稳定性,很多方案都会选择比较固定单一的采集方式来获取生物特征,但是这样的采集方式已经不能满足现代身份认证/识别系统的需求。复杂的身份识别采集场景,对于光照以及姿态都有很高的要求,而传统的特征提取方法,类似于 Gabor 等,都无法应付这样的复杂的采集场景。这就对特征提取算法自身的稳定性提出了更高的要求。

近年来,卷积神经网络在模式识别等领域大放异彩。网络可以在充分的数据下学习复杂情况下的稳定特征,让算法对于采集环境的条件变得更加宽松,也使生物特征身份认证的应用场景变得更加宽泛。可是,一般的神经网络都是做分类和回归的,怎么能够做到判断两个特征是不是同一个人的呢?这样我们就引出了今天的主题:使用深度神经网络的表征度量学习。
度量学习是什么?
传统机器学习中,很多任务都可以被建模为回归或是分类任务。这些任务都需要强标签,也就是有明显语义定义的标注数据,比如类别标签,或者是位置信息。然而近几年在表征学习领域,一种新的学习方式逐渐受到了学术界的关注,那就是度量学习。
度量学习旨在让模型学习样本与样本之间的相似度,鼓励模型学习 同类 与 不同类 之间的泛化度量(可以是欧氏距离,也可以是余弦相似度)。这个度量应该在整个数据上面都能展示同一性,也就是说在陌生数据下也应该有同样辨析同类异类的能力。
为了定义问题,首先我们需要一个度量空间 R^n 来度量两个样本的距离。这里我们使用 距离函数 d∣(R^n,R^n)→R 来描述两个样本的距离。那么我们就可以得到两个简单的目标:
在将两个问题共同优化的过程中,对于不同簇的约束需要转化成对偶问题,也就是将
转化为
为了避免在优化联合目标过程中梯度变成 0 的情况,我们就需要增加一个参数 m (在文章中通常会被称为 margin),使得损失函数能够产生有效的梯度。通过上面对优化目标的简单整理,我们就可以得到一个非常单纯的 铰链损失函数(Hinge Loss)也被称作 对比损失函数(Contrastive Loss):
其中,xa 代表锚点(anchor)样本,xp 代表 与锚点同类的样本(positive),xn 代表 与锚点异类的样本(negative)。[⋅]+代表 max{0,⋅},为了截断负值。
再会,Hinge Loss..
如果简单的将两个目标融合在一起,那么就会遇到一个优化问题。
首先,函数 d 对于变量应该是 凸(convex)的。明显地,−d 对于变量应该是 凹 (concave)的,因此我们不能保证其解的稳定性。
另一方面,Hinge Loss 对于 正样本,也就是同类样本过于严格了:损失函数并不会考虑同类样本内部的差异,这可能会导致比较严重的过拟合现象。外加复合函数凹凸性带来的不稳定性,这些很难保证 Hinge Loss 能达到期望的全局最优。因此为了避免同时优化两个目标的困境,我们需要改变思路:将两个目标简化为一个。
我们在上述的 铰链损失函数 中提到了,我们希望最小化类内距离,最大化类外距离。也就是我们的目标有两个:

也就是说我们要最小化类内距离的上界,同时最大化类间距离的下界。我们可以假定:
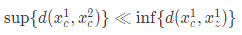
那么通过这个假设,我们可以添加一个松弛常量 m>0,便不难得到
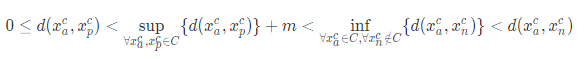
这样一来,我们就可以将两个目标转化为一个目标,也就是去优化
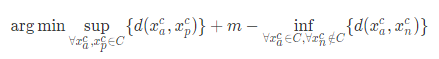
上面整理得到的损失函数是一个更加优美的一石二鸟的损失函数。当然,它的松弛形式已经是家喻户晓,那就是我们所说的 三元组损失函数(Triplet Loss)
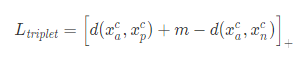
这里依然是为了优化而做了妥协,也就是使用了 max{⋅,0} 来截断 0 以下的损失。
Triplet Loss, 变身
对于 三元组损失函数,在近几年的文章中真的是层出不穷。但是本质仍然是没有改变的。所有的形式都是可以归结为上文中描述的紧致形式。我们来拿几个 loss 变种来推导一下。
1.Soft-Margin Triplet
很直观的,我们可以使用 log-sum-exp 的技巧来让线性空间的度量变得更明显。在这个案例中,也就是让目标与 0 的区分度更加明显。同时,LSE 的梯度相对于 max{⋅,0}也更加平滑,因此是很多文章喜欢使用的变种。Soft-marginal Triplet 可以定义为
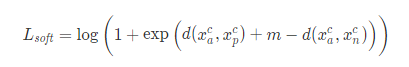
其实,这里的 Soft-margin 是可以反推回原始的 Triplet Loss 的。根据 Circle loss 中的启发,我们可以 re-parameterize Lsoft 为下面的形式。

通过应用 L’Hospital’s rule,我们可以得到 :

[2]
这就完成了 Soft-margin Triplet 与 Vanilla Triplet 的转化。
2.AM-Softmax [3]
通过上文得到的 Soft-margin Triplet,我们不难得到一个 野生的 AM-Softmax 损失
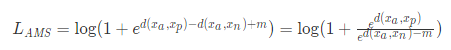
经过简化易得,

值得注意的是,如果我们将原文中的 余弦角度度量 替换成 广义的空间度量 d(⋅),那么文章就完全可以等价为 Soft Margin Triplet Loss。
结合原文来看,
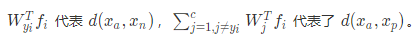
3.Angular Loss [4]
按照原文的损失函数设计来看,公式可以被简化为
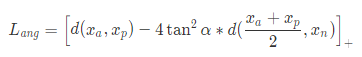
如果不顺着作者的思路,从我们上文提到 ArcFace 中累积类中心的思想引申过来,实际上 Angular Loss 就是通过正样本对的中心估计类中心。然而这个 loss 的设计建立在假定 (xa+xp)/2∈C,也就是默认 C是凸(convex)的 ,从而得到这个损失函数的。这个假设可能在真实场景中不成立。同样的问题也可能出现在 ArcFace 中,因为对类中心的估计可能并不会出现在实际的类当中。
4.ArcFace [5]
ArcFace 已经作为一种优秀的度量学习方法,被很多人脸识别系统应用。作为 AMS 的延伸,ArcFace 也同样适用了类似的损失函数设计。不过有一点不同的是,ArcFace 设计了一个 W∈R^(m×n),其中 m 是 Embedding 的宽度,n 是 数据库中的身份数。每一次损失函数训练的时候,训练样本会和每一个累积的类中心做距离损失。
这篇文章的核心就是在累积类中心的向量 wi ,并且将每个样本都去与这个 wi 做点积。用 arccos 将 cosθ(xW的结果) 转换成角度 θ,这样就可以将欧氏空间里的向量内积转换成角度,并用角度 margin m 来计算最小容忍角度的 cosine 范围 cos(θ+m) 。最后使用类似 AMS 的策略把度量学习 Loss 转化成 分类任务 Loss 进行监督。
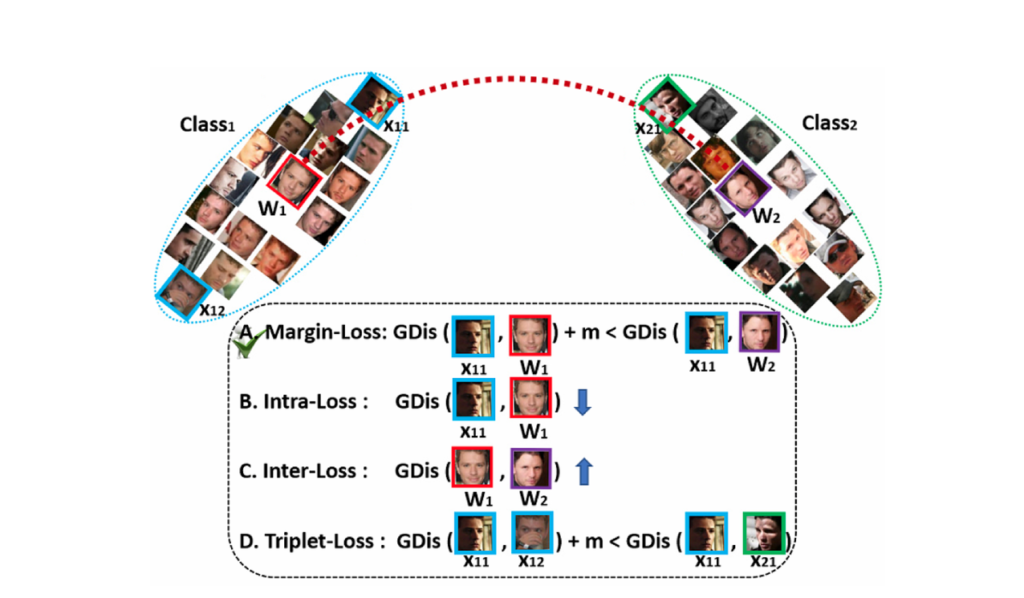
5.MagFace [6]
这篇工作是在 ArcFace 的基础上做的改动。文章中主要提出了两个根据特征离空间原点距离的 ai=∥fi∥ 监督策略
- 角度边界的选择是根据特征的离心距离来确定的。
- 添加了一个 Regularizer 来让离心越近的越近,离心越远的越远。
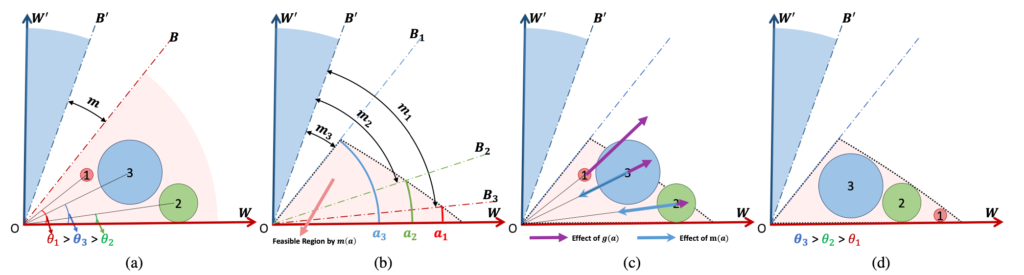
这样实际上就可以鼓励生成一个清晰样本更远,模糊样本更近的大致分布。根据实验发现,度量学习下的特征大致符合一个高斯分布。文章提出的方法可以将难以区分的样本(上图中 圆圈 3 表示的样本)拉的更近,让易区分的样本尽量分布在角度边缘。这样可以将高质量样本慢慢聚在更加远离空间原点的区域。
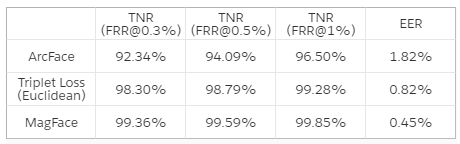
实验结果
在上文中,我们简单讨论并推导了一些现有的度量学习方法和他们之间的关系。接下来,我们使用了一些数据简略对比了一下度量学习在区分陌生类别的数据时的精度。结果如下表所示。

小结
本文粗略讨论了一些关于 度量学习 的技术。在这一领域从最朴素的 Hinge Loss 到 现存的 MagFace,无非都是基于一个基本的理念,那就是拉开异类,拉近同类。这样单纯的思想实际上背后上是类似弱监督的思想,也就是让数据本身定义自身的形状。
度量学习不需要强语义标签,仅仅需要知道两类不为同一类别即可。这样的特性让网络能够在更多的类别中获得更好的性能,同时也让网络获得了参与生物特征比对的能力。
同时,网络会在表征度量的约束下,对自然条件中复杂场景的生物特征进行聚合学习。这使得网络能够学习应该如何提取稳定生物特征,让生物特征能够随时随地、不分场景地得到精准的提取和识别。更加精准稳定的模型和算法,也大大拓宽了生物特征的应用场景,并提高了用户的使用体验。
[1] Miura N, Nagasaka A, Miyatake T. Extraction of finger-vein patterns using maximum curvature points in image profiles. IEICE TRANSACTIONS on Information and Systems. 2007 Aug 1;90(8):1185-94.
[2] http://incompleteideas.net/book/first/ebook/node17.html
[3] Wang F, Cheng J, Liu W, Liu H. Additive margin softmax for face verification. IEEE Signal Processing Letters. 2018 Apr 4;25(7):926-30.
[4] Wang J, Zhou F, Wen S, Liu X, Lin Y. Deep metric learning with angular loss. InProceedings of the IEEE International Conference on Computer Vision 2017 (pp. 2593-2601).
[5] Deng J, Guo J, Xue N, Zafeiriou S. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019 (pp. 4690-4699).
[6] Meng Q, Zhao S, Huang Z, Zhou F. Magface: A universal representation for face recognition and quality assessment. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021 (pp. 14225-14234).