
在墨奇科技,我们用基于向量(vector)和图(graph)的近似搜索算法,构建高精度的大规模图像搜索引擎。目前,在 20 亿级别的指纹图像上,我们可以做到精确搜索的秒级响应。在这个过程中,我们将英特尔®傲腾™持久内存融合到了图像搜索引擎中,使得系统的整体性价比得到了大幅度的提升。这个改进的核心是使用英特尔®傲腾™持久内存的 App Direct 模式代替内存作为向量和图索引结构的缓存,在维持较高性能的同时,大幅度降低了内存开销。下面我们开始介绍整体方案。
背景 – 墨奇图像搜索系统
下图是墨奇图像搜索系统的架构。在插入一张图片时,我们先将图片存储到分布式文件系统中,然后结合一些计算机视觉算法和深度学习模型对图像进行特征提取,图像的特征一般可以表示为向量或图。对于每张图像,我们首先用深度学习模型得到一个高维的向量表示(vector/embedding)。其次,我们会对图像进行特征点检测,我们将特征点当做点(vertex),在相似的特征点之间连上边(edge),组成一个图(graph)。图中的点和边有时候也会带上更多的信息,如点的属性(如位置、方向和类型)和点周围图像的向量表示。对于库中的所有候选图像,在提取出特征后,我们将特征均匀的分配到图像搜索服务器上,并在内存中建立索引。在搜索时,用户的图片在经过特征提取服务器之后提取出来的特征,会被发送到图像搜索服务器上进行检索。

我们的图像搜索服务器架构如下图所示。在图像搜索服务器中,我们将特征索引文件缓存在内存之中,搜索分为 GPU 检索和 CPU 检索两个步骤:我们先用 GPU 检索快速的筛选候选图片,然后再用 CPU 进行精确检索。关于在图像搜索中的异构计算(主要是 GPU),我们在《异构计算》中进行了介绍。图像搜索服务器的一个问题在于,为了实现高速的检索,它需要使用大量的内存来缓存特征索引文件,这大大提高了硬件成本。我们曾尝试将部分索引文件放到高性能的 NVMe SSD 上,发现对于性能有较大的损失。

什么是持久内存?
持久内存(英语:persistent memory,缩写 PMEM)是一种新的存储介质,它是一种驻留在内存总线上的字节可寻址(byte-addressable)的高性能非易失存储设备。由于 PMEM 驻留在内存总线上,它可以像 DRAM 一样访问数据,这意味着 PMEM 具有与 DRAM 接近的速度和延迟以及 NAND 闪存的非易失性。下图是 PMEM 和 DRAM 的实物图,可以看到,在外观和接口上,PMEM 与 DRAM 类似。

由于硬件技术的限制,存储设备商可以制造出容量小访问速度快但单价较贵的存储器(如 CPU Cache 和 DRAM),也可以制造出容量大访问速度慢而廉价的存储器(如硬盘和磁带),但很难制造出访问速度快容量大还很便宜的存储器。因此,现代计算机通常将存储器分成若干级,称为存储器层次结构(如下图),按照离 CPU 由近到远的顺序依次是 CPU 寄存器、CPU Cache、内存(DRAM)、SSD 闪存、硬盘和磁带,越靠近 CPU 的存储器容量越小访问速度越快但越昂贵。

如下图所示,PMEM 的出现,在存储器层次结构上增添了新的一层。PMEM 兼具 DRAM 和 SSD 的一些优点:
- PMEM 的容量通常远远大于 DRAM,而且也更廉价。
- 类似 SSD,PMEM 提供非易失性(non-volatile)存储,可以在不通电的情况下保证数据不受损。
- 类似 DRAM,PMEM 支持字节可寻址(byte-addressable),这意味着 CPU 指令可以直接存取 PMEM 上的数据,而不需要通过 I/O 总线上的 PCIe 接口。相比于对于 SDD 和硬盘的 I/O 操作,对于 PMEM 的访问节省一次驱动到操作系统的上下文切换(context switch),并且不存在由于块访问(block access)导致的读写放大问题,提升了 I/O 操作的效率。

持久内存上的使用
目前市场上较为成熟的 PMEM 产品只有英特尔®傲腾™持久内存。这节我们介绍傲腾持久内存的三种运行模式:内存模式(Memory Mode)、App Direct 模式和混合模式(Dual Mode)。通过利用这几种运行模式,用户可以灵活地利用傲腾持久内存支持不同的工作负载。
内存模式
在内存模式下,PMEM 的使用与 DRAM 非常相似。不需要特定的软件或更改应用程序,PMEM 会模仿 DRAM,使数据保持“易失性”。PMEM 使用易失性密钥加密数据,而秘钥在每个电源循环后都会清除,这样在断电重启后,PMEM 上的数据就像 DRAM 一样丢失了。 在内存模式下,PMEM 作为 DRAM 的扩展,并由主机内存控制器进行管理。 PMEM 与 DRAM 没有固定的比率,其混合取决于应用程序的需求。 就延迟特性而言,任何击中 DRAM 缓存的数据会提供小于 100 纳秒的延迟。 任何高速缓存未命中都会流向 PMEM,这将在亚微秒范围内提供延迟。

除了不能利用 PMEM 的非易失性,我们在将图像搜索服务器运行在 PMEM 的内存模式上时,遇到的另一个问题是程序的性能难以预料。原因是内存模式使用 DRAM 进行缓存,如果缓存命中,那么访问 DRAM 的延迟在 14 ns 左右,但如果缓存失效,访问 PMEM 的延迟在 350ns 左右,这个性能差了 20 多倍。由于缓存的算法是由操作系统控制的,不受应用程序的控制,应用程序的性能会由于当前服务器上的工作负载,产生很大的性能波动。
App Direct 模式
在 App Direct 模式下,应程序可以独立的使用 DRAM 和 PMEM 资源,更加灵活。应用程序中需要较快访问的数据存在 DRAM 中,而其余的数据则可以放在容量更大的 PMEM 上。 在 App Direct 模式下,PMEM 中的数据在断电后保持不变,这可以大幅度地减少重新启动后应用程序的加载时间(比如一个图像搜索引擎启动时要将索引文件加载到内存中)。此外,在 App Direct 模式下,PMEM 仍然像内存一样可以通过字节访问(byte-addressable),这避免了使用其它存储介质(如 NVMe SSD)时的读写放大问题。
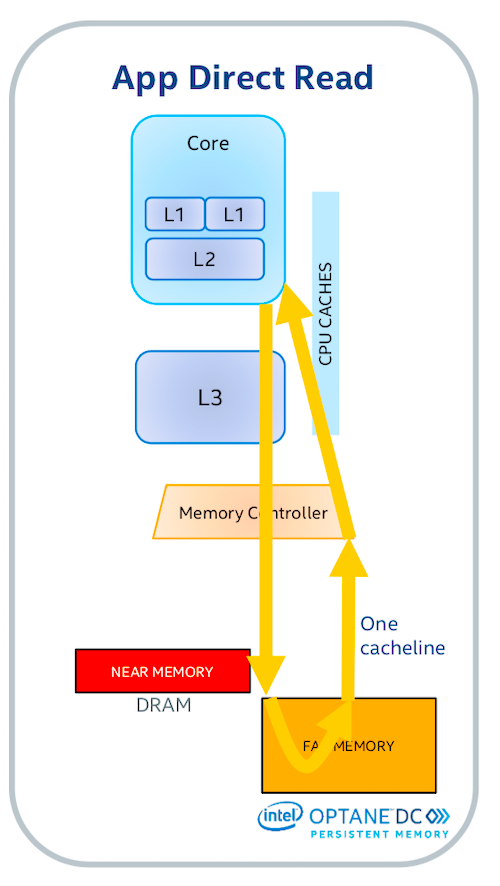
但是,App Direct 模式要求我们对应用程序进行一些修改,以利用 PMEM 的这些良好特性。一个办法是使用英特尔推出的 Persistent Memory Development Kit (PMDK)。PMDK 包含了一系列旨在方便 PMEM 应用开发的函数库和工具。另一个方法是直接在 PMEM 上创建支持 devdax 的文件系统(如 XFS),然后利用 Linux 的内存映射文件 mmap 来直接读写 PMEM 上的数据。
混合模式
在混合模式下,我们可以将部分 PMEM 配置成内存模式,部分 PMEM 配置成 App Direct 模式,兼具两种模式的优点。
基于 PMEM 改写图像搜索服务器
回顾第一节的介绍,我们的图像搜索算法分成 GPU 检索和 CPU 检索两个阶段。结合 profiling 的结果,我们利用高性能计算分析模型 Roofline model 得到了如下结论:
- GPU 检索接近于 memory-bound,主要瓶颈在于内存与 GPU 之间传输数据的带宽。同时,由于 GPU 的索引文件体积较小,因此我们将 GPU 的索引文件通过 pinned memory 的方式放置在主机的 DRAM 上。
- CPU 检索接近于 compute-bound,瓶颈主要在 CPU 的算力。同时,由于 CPU 的索引文件体积较大,我们选择将 CPU 的索引文件放在 PMEM 上。

最后,介绍一些在持久内存上编程需要注意的事项:
- 数据持久化:数据写入 PMEM 后,需要 flush 才会被持久化。例如:
- 使用
mmap中的msync()和 PMDK 中的pmem_persist(); - 如果写汇编则可以用
sfence、clwb
- 使用
- 数据一致性:与 SSD 和硬盘不同,PMEM 写操作保证原子性的单位是 8 byte,在使用一些之前用在 disk 上的数据结构时需要注意。
- 内存泄漏:由于 PMEM 上的数据是持久的,重启进程或者服务器之后,PMEM 中内存泄漏都仍然存在,除非我们主动丢弃 PMEM 中的数据。因此要注意在 PMEM 编程中的内存泄漏问题。
- 字节可寻址(byte-addressable):PMEM 的读写操作不需要像 SSD 和硬盘那样对齐到 4KB/8KB 的空间上,减少了读写放大。
- 错误处理:需要额外处理 PMEM 引发的硬件错误。
实践与测试结果
这节中,我们介绍如何配置一台带有 PMEM 的服务器,以及我们改进后的图像搜索服务器的性能。
下面是我们服务器的硬件配置:
| 组件 | 配置 |
| CPU | 2 x Intel(R) Xeon(R) Gold 6240 CPU @ 2.60GHz |
| DRAM | 384 GB (12 x 32 GB Samsung DDR4 @ 2666 MT/s) |
| PMEM | 1.5 TB (12 x 128 GB Intel® Optane™ Persistent Memory) |
| GPU | 2 x NVIDIA 1080 ti |
| NVMe SSD | 4 x Intel® DC SSD P3700 |
| Platform | Supermicro SYS-4029GP-TRT |
操作系统的配置:
- Ubuntu 16.04
- Linux Kernel 4.4.0-141
- kernel module: nvdimm driver / Direct access (DAX) support / Block translation table (BTT)
- 注:由于 Linux 对 PMEM 的支持还不太稳定,不同的 kernel 版本对性能影响较大
需要安装的 PMEM 管理工具:
- ndctl: https://github.com/pmem/ndctl
- ipmctl: https://github.com/intel/ipmctl
现在,我们可以开始配置 PMEM 了:
- 创建一个配置(称作 memory allocation goal),将所有的 PMEM 分配到 App Direct 模式:
- 重启服务器,确认分配信息:
- 创建一个 namespace:
- 查看代表 PMEM 的块设备,可以看到 PMEM 被分成了 2 个块设备:
- 用 XFS 格式化 PMEM 的块设备:
- 挂载 PMEM 上的文件系统:
$ ipmctl create -goal
$ ipmctl show -memoryresources
Capacity=5900.5 GiB
MemoryCapacity=0.0 GiB
AppDirectCapacity=5892.0 GiB
UnconfiguredCapacity=0.0 GiB
InaccessibleCapacity=8.2 GiB
ReservedCapacity=0.3 GiB
可以看到,一共 6 TB 的 PMEM 都被分配成了 App Direct 模式。
$ ndctl create-namespace
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
pmem0 259:0 0 2.9T 0 disk
pmem13 259:1 0 2.9T 0 disk
$ mkfs.xfs /dev/pmem0
$ mkfs.xfs /dev/pmem13
$ mount -o dax /dev/pmem0 /mnt/pmem0
$ mount -o dax /dev/pmem13 /mnt/pmem1
完成这些操作后,/mnt/pmem{0,1} 目录就可以作为持久化的存储来使用。我们一般会在这个目录下创建索引文件,使用 mmap 访问。
我们在这个平台上测试了我们的图像搜索服务器性能。其中,GPU 的索引文件总是放在 DRAM 中,然后我们测试了将 CPU 索引文件放在 DRAM、PMEM 和 NVMe SSD 中这三种情况。下图中展示了三种情况下的数据库容量、搜索吞吐量和搜索延迟,所有数据都按照 DRAM 的性能进行了正则化(normalize)。从图中可以发现:
- 由于 DRAM、PMEM、NVMe SSD 的容量依次递增,使用 PMEM 和 NVMe SSD 相比只使用 DRAM 可以容纳更多的数据,也就是说性价比更高。
- 在搜索的吞吐量和延迟两项指标上,PMEM 只比 DRAM 差了 10% 左右,而 NVMe SSD 的搜索性能相差较远。这说明 PMEM 带来更高性价比的同时,性能损耗比 NVMe 小的多。

总结
持久内存(PMEM)的出现,为 AI 算法和系统的设计带来了新的机遇和挑战。PMEM 作为存储层次中新的一层,有一些独特的优势:
- 相比于上一层的 DRAM,PMEM 可以降低图像搜索系统的硬件成本,同时提高系统的可靠性。
- 相比于下一层的 NVMe SSD,PMEM 可以提高图像搜索系统的吞吐量,并降低搜索的时延、提高用户体验。